Flow Matching
Introduction
Flow matching is a fundamental algorithm used in state-of-the-art image generation models as well as VLA (vision-language-action) models in robotics. In particular, (Physical Intelligence, 2025) and X-VLA (Zheng et. al., 2025) are notable high-performing examples of successful flow matching used in robotic manipulation.
I thought it would be interesting to dive into the mathematical derivations behind algorithm, standing on the shoulders of many excellent existing resources explaining it :)
What is Flow Matching?
The aim of flow matching is to generate a sample from an unknown probability distribution.
For example, let’s consider an image generation model. Say we have a dataset of 50 cat pictures and we want to generate another picture. The unknown probability distribution here is the mathematical function describing the likelihood of all cat pictures. We cannot know this function directly; we only have samples (our dataset). We want to sample from this unknown probability distribution to generate a picture that is distinct to the ones in the dataset, but one that we would still classify as a cat.
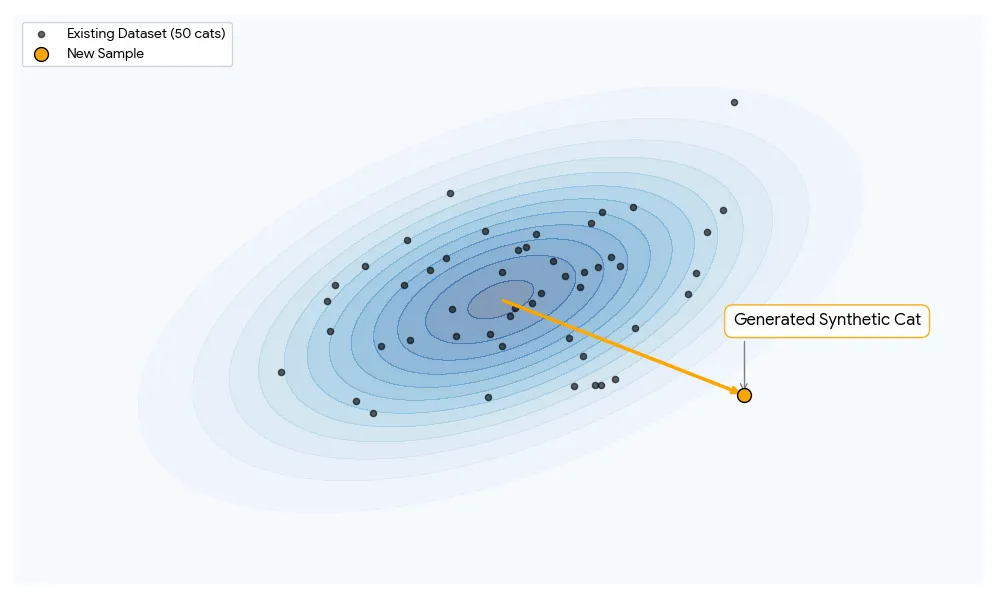
Blue represents the entire cat picture distribution, black dots represent our limited dataset.
How might we accomplish this? Flow matching proposes we build a path translating from a known distribution to this unknown distribution, so that if we follow this path, we will always end up at some point in the unknown distribution.
It’s sort of like a treasure map. It tells you where to go from where you started, and if you dig around the target, you’re bound to find treasure.
Let’s call the unknown target distribution , and the known distribution , where . Let’s set it such that at time , , at , , so as we move forward in time we move closer and closer to the target distribution.
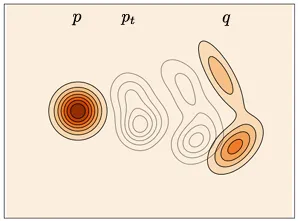
is known, is target, is our path (Lipman et. al., 2024)
Now let’s construct a probability path that fulfills these requirements.
Constructing the Probability Path
At a given time , should give us the intermediate probability distribution (the grey distributions in the image above) that our points could possibly be in. By the marginal Law of Total Probability, given two continuous random variables and ,
Thus, we can derive the probability path below! Given an arbitrary time and ,
As we can see, by defining as a Gaussian with and , we can intuitively linearly interpolate over the variable from to . This specific probability path is the conditional optimal-transport or linear path.
Let’s define as the random variable given time using the Reparameterization Trick.
Now we have in terms of and .
Let’s take a step back and remind ourselves of the goal. Given a sample from a known probability distribution, we want to be able to map it to a sample from an unknown probability distribution. We now know how to describe a relationship between the probability distributions and by interpolating over intermediary probability distributions , but is still incalculable without knowing what is.
Additionally, this is not the function input/output we want. We want to be able to map from an input, to some output when .
Defining Flow and Vector Fields
This is where flow and vector fields come in.
Let’s define a vector field such that given coordinate and time value , outputs the direction to move from that point.
Let’s further define a flow such that given a starting point and , it returns the coordinates of that point as we follow the vector field over time.
The relationship between the two can be defined as
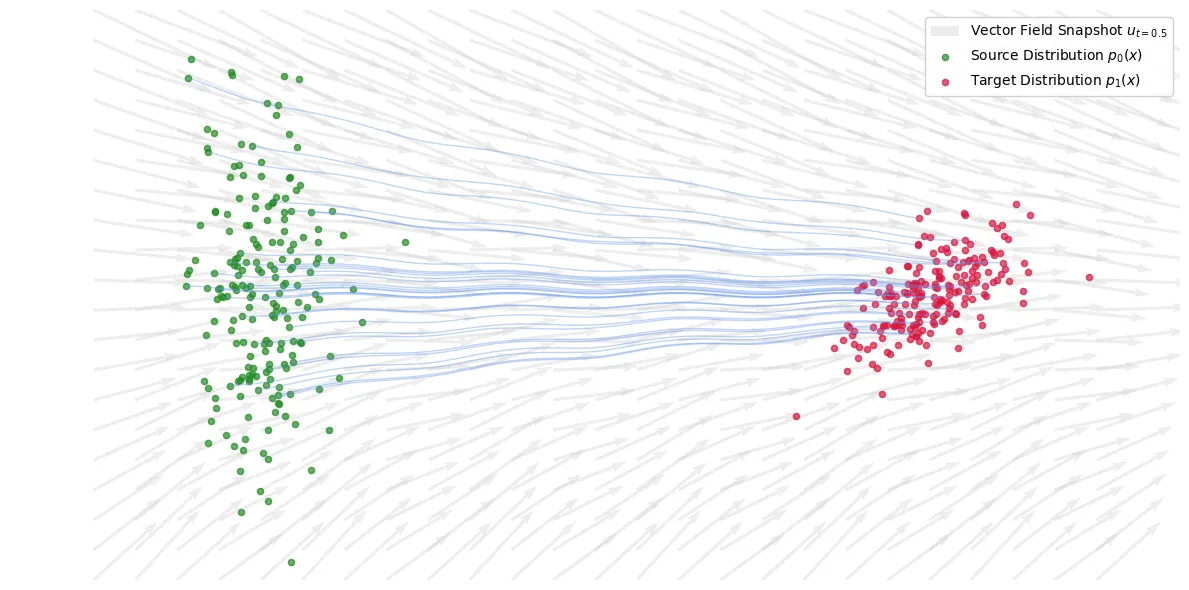
Arrows represent the vector field, the blue lines represent the flow given a starting input sampled from
In the image above, we can see that as we move forward in time, we follow the vector field defined by the grey arrows, and our path that we’re creating is our flow!
For this vector field specifically, let’s define such that it creates the probability field . This means that if we (hypothetically) sampled 1000 points from , found their position at after following , it would create the density represented by .
This is an important enough concept to reiterate. A vector field dictates which way the point moves at a given time step. The flow represents the path a particle takes, given a starting location and what time step we’re at. The probability path represents the density of those particles.
(I’d recommend watching 3Blue1Brown’s video on this - his visualizations are extremely helpful)
Now we finally have the function we wanted! A vector field tells us how to move from a point in to a point in . If we’re able to learn the correct vector field, we can generate any photo from our target distribution.
We can simply define the flow matching loss as
where is our neural network parameterized vector field. Minimizing this means our neural network perfectly matches the target vector field .
Unfortunately, calculating this loss function is intractable.
Simplifying the Intractable Loss Function
Let’s first show why it’s intractable by deriving an equation for .
You’ll notice that I began talking about particles rather than points: some students of physics may recognize this as fluid dynamics. Fluid dynamics theory further tells us that through the Continuity Equation,
where is divergence, defined by
where x is a single point.
Multiplying and gives us the probability current (or flux), as represents the density at a point and represents the velocity of that point. Thinking about this in terms of liquids and a hose,
- low density and high velocity => medium amount of water coming out
- high density low velocity => medium amount of water coming out
- high density high velocity => high amount of water coming out
Flux represents how much water is flowing through a point at a given time.
Divergence defines how much a vector field is expanding / compressing at a specific point. Interpreting the continuity equation, if divergence is positive and the flux is expanding, then the change in probability (density) will be negative, meaning that more water is escaping. If divergence is negative and the flux is compressing, then the change in probability is positive, as the water is moving slower and thus more dense.
We can attempt to solve for now. Starting with the Continuity Equation:
Substitute the marginal definition into the first term:
Move the time derivative inside the integral and substitute the conditional continuity equation :
Rearrange to equate the divergence terms:
Removing the divergence operator implies equality of the fields. Solving for yields:
Unfortunately, we then find that is intractable, as finding the integral over of this requires us to check every possible image to calculate it (and it’s impossible to check every single possible cat photo in existence).
Instead, we can simplify this by choosing a single objective, by fixing to be a single target example (i.e. an image in our dataset). Then we have an equation for which only depends on our Gaussian sample and :
In this case, rearranging the identity by differentiating Equation 14 yields
(Technically velocity fields should be a function of the current location not the target location, so you may rewrite this as , but for our purposes they are equivalent.)
Finally! We have a much simpler velocity field function that we can now easily compute the MSE of, yielding the Conditional Flow Matching loss function.
At a high level, we are just stating to match a vector field that results in a linear path pointing from to . Does this work? Finding the derivative of our earlier loss function and this one will yield the same result, showing they are equivalent!
We can see this in example flow matching code (Lipman et. al., 2024):
import torch
from torch import nn, Tensor
class Flow(nn.Module):
"""
Parameterized vector field.
Input: [x_t, t]
Output: u(x_t)
"""
...
...
# Initialize flow matching model, MSE loss function
flow = Flow()
loss_fn = nn.MSELoss()
# x_1 sampled from target distribution, x_0 sampled from Gaussian
# Calculate delta between the two
dx_t = x_1 - x_0
# Find MSE between u^theta_t(x_t) and x_1 - x_0!
# Note that x_t represents the coordinates of the point while t is a float between [0, 1] representative of the time
loss_fn(flow(x_t, t), dx_t).backward()I’ll leave the post there - maybe I’ll write more later on. Further reading would include various ODE solvers, score-based generative modeling, and diffusion models!
Resources that greatly helped me: